知行合一,止于至善
千里之行,始于足下;合抱之木,生于毫末;九层之台,起于累土lucene索引文件格式[分析]
为了简单,本文基于lucene 1.4.3 分析,鄙人一直坚信,越古老的东西越质朴,便于分析。1.4.3是我能找到最古老的版本了,在lucene的归档包中能下载到,也可以从我的网盘中下载pdf本文主要是基于notepad++对磁盘中各个文件进行16进制转储分析
.fnm 文件
存放 field name,需要注意的是第一个元素为空白
本文lucene索引文件格式[分析]由javacoder.cn整理,转载请注明出处,谢谢 , 测试代码下载
.fdt, .fdx 文件
stored fields存放文件,比如"description"这个域分词后,我们即希望能根据term搜索, 又希望能获取完整的描述, 那么需要对"description"域完整的内容进行存储
.fdt 存储数据
.fdx 每个doc 的field data在.fdt中的存储,一个给定的docId, 它对应的值在.fdx的docId*8 偏移处。
.tis[terminfos],.tii [term info index] 文件
.tis, term 存储文件
FreqDelta, .frq文件中对应的TermFreqs记录与前一个term的TermFreqs偏移量
ProxDelta .prx 文件中对应的TermPositions记录与前一个term的TermPositions偏移量
.tii 每间隔TermInfosWriter.indexInterval=128个元素, 对.tis进行一次索引, .tii便于放在内存中加速查找。
.frq
在一个document中各个term出现的频率
.prx
每个term在每个document中出现的位置(term和.tis文件中的位置隐式关联,一个term在一个文档中出现的次数从.frq中隐式关联)
下面以一个具体的实例来认识各个字段。主要是tis文件和frq文件
测试中使用的document内容如下:
Map<String, String> item = new HashMap<String, String>();
item.put("username", "huang javacoder test");
item.put("description", "handsome test for handsome age");
App app = new App(true);
app.index(item);
item.put("username", "rex");
item.put("description", " a fabulious handsome man");
app.index(item);
.tis文件格式对应的伪vo
{
UInt32 TIVersion
UInt64 TermCount,
UInt32 IndexInterval,
UInt32 SkipInterval,
[
TermInfos {
Term{
VInt PrefixLength,
Suffix{VInt,char[]},
VInt FieldNum
}
VInt DocFreq,
VInt FreqDelta,
VInt ProxDelta,
VInt SkipDelta
}
]
}
16进制转储为
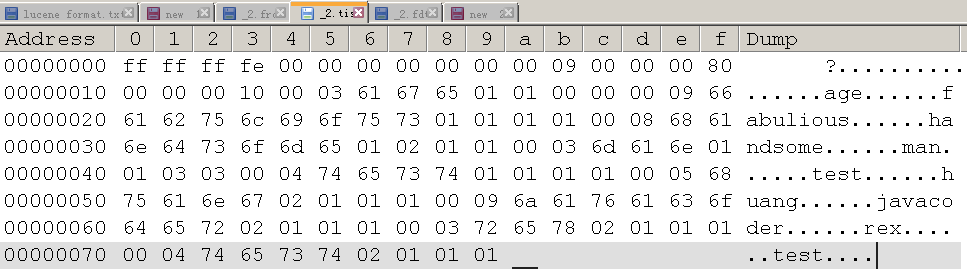
.frq 文件格式对应的伪vo
[
DocDelta VInt or {VInt, VInt}
...
]
如果该term只在一个文档中,将docId和频次 通过位操作合成一个VInt, (docId >>> 1) | 1
测试数据对应的二进制转储为
01 03 20 02 03 03 01 01 01 03 01
根据规格还原
term docId-freq
--------------------------
age 0-1
fabulious 0-1
handsome 0-2, 2-1
man 2-1
test 0-1
huang 0-1
javacoder 0-1
rex 2-1
test 0-1
总结:tis的DocFreq 字段定义了有多少个文档含有该term,FreqDelta 字段存储了.frq中该term在哪些document中信息的偏移量
Posted in: Lucene

Comments are closed.